La pierre tombale du programmeur

Vers 1960, Howard Bromberg quitta son bureau du RCA (Radio Corporation of America) dans un accès de frustration contre le comité qui concevait COBOL. Le travail de spécification avançait trop lentement, et un coup de fil tendu un vendredi après-midi avec le président du comité, Charles Phillips, venait de mal se terminer. Sur le chemin du retour, il aperçut une marbrerie funéraire à la sortie d’une autoroute, s’y arrêta, et acheta une pierre tombale en marbre. Il y fit graver un seul mot : COBOL. Puis, avec ses voisins, il l’emballa dans une caisse, et l’envoya à Phillips au Pentagone, en port dû.
C’était une blague. Soixante-six ans plus tard, la pierre tombale est exposée au Computer History Museum. COBOL, lui, n’a pas été enterré. Les estimations du volume de COBOL en production aujourd’hui varient largement, d’environ 250 milliards de lignes (Open Mainframe Project) à plus de 800 milliards (une enquête Micro Focus de 2024 menée auprès de 1 100 ingénieurs dans 49 pays). Tous les comptages sérieux atteignent les centaines de milliards. C’est lui qui faisait tourner les systèmes d’allocations chômage américains qui ont craqué en 2020. C’est lui qui fait tourner l’essentiel de la banque mondiale.
Bromberg était frustré par un comité. Il ne prédisait pas sérieusement la mort de son propre langage. Mais dans les décennies qui ont suivi cet épisode, au moins sept autres personnes ont gravé des pierres tombales pour la profession de programmeur elle-même, et le pensaient sérieusement. L’occupant continue de manquer à l’appel.
Je veux dire d’emblée que cet essai ne porte pas vraiment sur la question de savoir si la dernière tombe en date restera elle aussi inoccupée. Les données historiques répondent suffisamment bien à cette question, et je vais les parcourir brièvement. Plus importante est la question sous-jacente, que le débat sur le remplacement a presque entièrement masquée :
Même si les effectifs de la profession se maintiennent, qu’advient-il du pipeline qui produit les ingénieurs seniors ?
Cette question n’a pas de réponse historique. Et c’est la question sur laquelle un dirigeant d’ingénierie peut réellement agir ce trimestre. Qu’il s’agisse de calibrer les ratios junior/senior pour 2027, de décider dans quelle formation investir, ou de défendre des effectifs face à un CFO qui a lu les déclarations d’Amodei et conclu que cette ligne budgétaire pouvait être coupée.
Brève histoire de la pierre tombale
Le schéma est assez vieux pour avoir son propre cliché. Je m’en tiendrai à ceux qui ne présentent aucune ambiguïté, et qui suffisent largement :
- James Martin, préface de 1982 à Application Development Without Programmers : « Le nombre de programmeurs disponibles par ordinateur diminue si vite que la plupart des ordinateurs devront, à l’avenir, fonctionner au moins en partie sans programmeurs. »
- Ed Yourdon, Decline and Fall of the American Programmer, 1992 : les programmeurs américains seraient remplacés par une main-d’œuvre offshore moins coûteuse utilisant des outils CASE.
- John McCarthy chez Forrester, 2002 : 3,3 millions d’emplois de cols blancs américains seraient délocalisés en quinze ans, l’IT en tête.
- Gartner, juin 2021 : d’ici 2024, 80 % des produits et services technologiques seraient construits par des professionnels hors IT.
- Jensen Huang au World Government Summit, février 2024 : « Tout le monde est désormais programmeur. »
- Mark Zuckerberg chez Rogan, janvier 2025 : Meta et ses pairs déploieraient des « mid-level software engineers » IA dans l’année.
- Dario Amodei au CFR, mars 2025 : l’IA écrirait 90 % du code dans trois à six mois et la quasi-totalité dans douze.
En lisant ces déclarations d’affilée, ce qui frappe, c’est combien le langage change peu. Les chiffres bougent entre 80 %, 90 %, « mid-level », mais la forme est identique. Un nouvel outil permet à des non-programmeurs de construire des logiciels. La profession s’effondre. L’effondrement est imminent.
Chaque prédiction était vérifiable, et les données du recensement les démentent toutes. Prenons l’évolution de l’emploi IT aux États-Unis :
- 450 000 en 1970
- 781 000 en 1980
- 1,5 million en 1990
- 3,4 millions en 2000.
En mai 2024, 5,19 millions d’Américains travaillaient dans des métiers « Computer and Mathematical », dont 1,65 million de Software Developers. À travers chaque vague qui était censée mettre fin à la profession, la demande a été à la hausse.
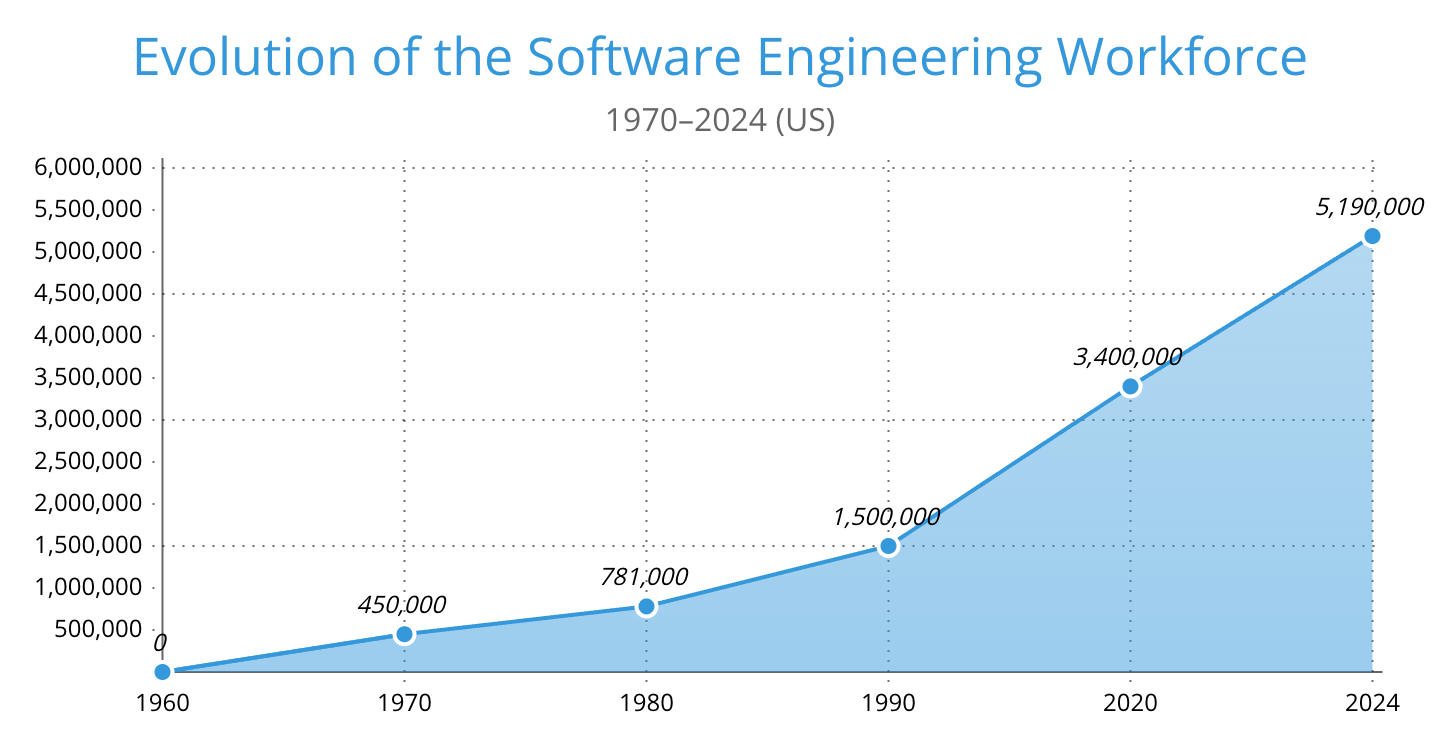
À noter, les codes des catégories professionnelles américaines ont été redéfinis en 2000, reclassant des millions de « programmeurs » en « ingénieurs logiciels » et produisant un déclin apparent dans les données Computer Programmers du BLS. En mars 2025, Fortune titrait sur l’emploi de programmeur atteignant son plus bas niveau depuis 1980. C’est techniquement vrai pour ce seul code mais presque entièrement un artefact de reclassification. Le travail n’a pas disparu, il a évolué.
Ce qui s’est réellement produit à chaque vague, c’est un changement de composition, pas une chute des effectifs. Les 4GL ont créé des spécialistes des 4GL. CASE a échoué purement et simplement, et Yourdon lui-même a rétracté ses prédictions en 1996 dans Rise and Resurrection of the American Programmer après l’arrivée des données d’adoption. Visual Basic a produit environ 3,5 millions de développeurs amateurs, et l’emploi IT américain a augmenté de 127 % dans la décennie suivante, la plus forte croissance décennale de la série BLS. Le low-code a atteint un marché réel mais modeste d’environ 26,9 milliards de dollars en 2023, tandis que l’emploi des développeurs logiciels américains est passé de 1,1 million en 2015 à 1,7 million en 2024, au pic de la hype.
La mesure de la vague actuelle
Le calendrier de mars 2025 est maintenant révolu. La fenêtre de trois à six mois pour 90 % de code écrit par IA et celle de douze mois pour la quasi-totalité du code se sont toutes deux refermées. Les chiffres montrent que la trajectoire sous-jacente ne s’aligne pas sur la prédiction. Satya Nadella a chiffré la part de code écrit par IA chez Microsoft à « 20 à 30 % » à LlamaCon en avril 2025. Sundar Pichai a donné un chiffre similaire lors de la conférence sur les résultats du T3 2024 d’Alphabet. Le signal des grandes organisations productrices de code se situe dans la fourchette 20–35 % et semble se stabiliser. Ces données restent à surveiller, mais elles sont tout de même un ordre de grandeur en dessous de la prévision.
Les chiffres sur l’impact de l’IA sur la productivité pour 2025–2026 pointent dans la même direction que les vagues précédentes. L’essai contrôlé randomisé de METR de juillet 2025, portant sur seize développeurs expérimentés travaillant sur leurs propres dépôts open-source matures, a montré que les développeurs prévoyaient une accélération de 24 % grâce à Cursor et Claude, l’estimaient à 20 % a posteriori, et qu’on a mesuré un ralentissement de 19 %. Une étude de suivi en février 2026 avec 57 développeurs sur 143 dépôts a produit les mêmes conclusions : un petit effet négatif. METR a cependant conclu que le signal était devenu peu fiable en raison d’un biais de sélection et a modifié son protocole expérimental.
L’enquête DORA 2024 auprès d’environ 3 000 ingénieurs a constaté qu’une augmentation de 25 % de l’adoption de l’IA était corrélée à une baisse de 1,5 % de la vélocité de livraison et de 7,2 % de la stabilité. L’édition 2025 a inversé le résultat sur la vélocité, mais pas celui sur la stabilité. Cela mérite qu’on s’y arrête, parce que cela signifie que l’histoire de la productivité s’améliore tandis que celle de la qualité ne s’améliore pas, et seule la seconde s’accumule dans le temps. GitClear (qui vend de l’analytique sur la qualité de code, donc à pondérer pour l’incitation commerciale) a constaté que les lignes copiées-collées sont passées de 8,3 % à 12,3 % entre 2020 et 2024, tandis que les lignes refactorées chutaient de 24,1 % à 9,5 %. L’enquête de Stack Overflow montre que l’opinion favorable sur les outils d’IA décroît de 77 % en 2023 à 60 % en 2025, un glissement qui traverse tous les niveaux d’expérience.
Pendant ce temps, le BLS projette une croissance de 15 % pour les développeurs logiciels de 2024 à 2034 (US), ajoutant environ 129 200 ouvertures par an. Cette projection a été publiée en 2025, après la prédiction d’Amodei.
L’objection, cette fois
Voici la version la plus solide de l’argument inverse.
Les outils antérieurs étaient limités. Les 4GL avaient une grammaire fixe. CASE opérait sur un ensemble fixe de diagrammes. Le low-code tourne dans un runtime prédéfini. Les grands modèles de langage n’ont pas ces limites. Ils peuvent être généralisés à un ensemble de problèmes qui grandit avec la puissance de calcul ; les benchmarks ont dû être réinventés à plusieurs reprises par des versions plus difficiles à mesure que les nouveaux modèles les rendaient obsolètes. On ne peut donc pas se baser sur des données historiques et des analyses rétrospectives quand le phénomène sous-jacent est qualitativement nouveau.
Tout cela est vrai. Et c’est précisément pour cela que le problème de la complexité empire, plutôt que l’inverse.
Les programmeurs n’ont jamais été indispensables pour leur capacité à taper sur un clavier. Ce sont les personnes qui gèrent la complexité par l’abstraction : compresser sept choses en une, récursivement, jusqu’à ce qu’un système trop complexe pour n’importe quel cerveau humain devienne pensable. Ce problème ne devient pas plus simple quand le code est moins cher à générer. Il devient plus complexe : plus de code à raisonner, plus de systèmes en interaction, plus de modes de défaillance à tracer.
Un exemple concret tiré de mon expérience. J’ai été appelé sur un incident en production sur un service de paiement. Le symptôme : des timeouts intermittents quand la charge passe un certain seuil. Un assistant IA, à qui l’on donne la stack trace et la fonction fautive, va générer un correctif plausible : ajouter un retry, augmenter un connection pool, mettre en cache un lookup. Et n’importe lequel de ces correctifs peut passer la compilation et les tests. Toutefois, la véritable source du problème était qu’une clé d’idempotence était dérivée du timestamp de la requête arrondi à la minute, ce qui faisait que deux retries dans la même minute se fondaient silencieusement en un seul paiement au lieu de deux, ce qui ressemblait à un timeout côté appelant parce que la deuxième réponse n’arrivait jamais. Trouver cela demandait de lire quatre services, de se souvenir que le processeur de paiement avait modifié sa fenêtre de déduplication dans un ticket six mois auparavant, et de reconnaître un schéma issu d’un incident similaire passé. Aucune quantité de génération de code ne se substitue à cette chaîne de pensée. Les correctifs générés auraient fait disparaître le symptôme et laissé le système de paiement cassé.
Le travail de jugement consistait à savoir quelle hypothèse poursuivre, quel contexte historique appliquer, quand cesser de faire confiance à ce que dit le code et commencer à lire ce qui se passe réellement en production. C’est là qu’un ingénieur gagne son salaire. Ce travail devient plus important, pas moins, à mesure que les parties mécaniques du code sont automatisées.
Ce qui m’amène à mon point. L’IA ne remplacera pas les ingénieurs logiciels, mais ces mêmes outils qui n’arrivent jamais à éliminer la profession sont peut-être en train de briser le mécanisme spécifique par lequel la profession se reproduit. Les effectifs totaux tiennent toujours, la projection BLS dit qu’ils tiendront, mais le pipeline qui produit les seniors s’amincit silencieusement.
La question de la reproduction
Les ingénieurs ne naissent pas seniors. Ils le deviennent par un apprentissage d’environ dix ans pendant lequel un junior fait un travail qui, rétrospectivement, est essentiellement mécanique : écrire des endpoints CRUD, corriger des bugs de null pointer, lire du code existant jusqu’à ce que l’architecture s’éclaire, déboguer sous pression, livrer de petites features de bout en bout, regarder son propre code casser en production. Aucune de ces tâches individuelles ne demande un jugement profond. Ce qu’elles produisent, cumulativement, c’est la bibliothèque de patterns sur laquelle se construit la seniorité.
Apprendre que les retries sans clé d’idempotence sont un piège nécessite d’y être tombé un jour. Apprendre à lire une stack trace rapidement nécessite d’avoir passé trois ans à en lire lentement. Apprendre à reconnaître quand un document de design est trop vague, et le coût que ce manque de clarté engendre, nécessite d’avoir eu à en implémenter.
Le jugement est en aval du travail mécanique. C’est en tout cas mon hypothèse la mieux étayée, pas encore un fait prouvé. La preuve directe la plus solide vient des données GitClear, qui méritent un examen plus attentif. Les lignes copiées-collées sont passées de 8,3 % à 12,3 % ; les lignes refactorées sont tombées de 24,1 % à 9,5 %, soit une compression d’environ un tiers. Le refactoring n’est pas une activité esthétique. C’est le mécanisme par lequel un ingénieur démonte un système qui fonctionne, l’optimise et le remonte, et la séquence démontage-optimisation-remontage est la façon dont le modèle mental du système se construit. Un junior qui refactore une fonction la comprend d’une manière qu’un junior qui demande à un LLM de la lui expliquer n’atteint pas. Un volume de production en hausse alors que le refactoring s’effondre, c’est exactement le signal de l’effondrement de la formation du jugement.
Ce qui me ferait changer d’avis, et ce dont le secteur a besoin, c’est une étude longitudinale suivant les juniors qui ont commencé après l’adoption de l’IA par rapport à la cohorte de 2019, à ancienneté équivalente, sur trois métriques précises :
- Temps moyen de remédiation d’incidents originaux (incidents dont le pattern n’est pas dans le corpus d’entraînement du modèle)
- Taux d’escalade vers les seniors sur tickets non routiniers
- Performance de jugement architectural en revue de code sans assistance IA.
Si la cohorte post-IA rejoint la cohorte de 2019 sur ces métriques d’ici cinq ans, j’ai tort, et la thèse de l’apprentissage-par-IA est juste. Aucune étude de ce genre n’existe encore, ce qui représente la lacune de recherche la plus importante du secteur.
Les preuves complémentaires fournissent des signaux faibles mais cohérents. Stack Overflow 2025 montre une large chute de l’opinion favorable sur les outils d’IA, de 77 % en 2023 à 60 % en 2025, plus prononcée chez les développeurs professionnels (le groupe qui devenait senior en faisant le travail mécanique). Le pattern que je continue d’entendre de la part des engineering managers avec qui j’ai pu échanger est cohérent également. Un directeur l’a formulé ainsi : « La cohorte de 2023 débogue en demandant au modèle. La cohorte de 2019 débogue en lisant. Quand quelque chose d’étrange arrive en production à 3 heures du matin, je peux dire en dix minutes laquelle des deux cohortes est d’astreinte. » Ce n’est pas que les jeunes ingénieurs sont moins bons dans l’absolu. Ils sont souvent plus rapides sur les tâches bien cadrées. C’est qu’ils sont moins exposés au type de problèmes sur lesquels le modèle ne peut pas les aider. Ceux où l’intuition doit venir d’eux-mêmes.
Les limites de l’apprentissage assisté par IA
Peut-être que l’apprentissage assisté par IA produit de meilleurs juniors, et non l’inverse. Un junior en 2020 apprenait du senior qui se trouvait être à portée de voix ou de clavier. L’apprentissage n’était ni gratuit ni auto-organisé. Il était radicalement inégal, dépendait de la chance et de qui étaient ses premiers collègues. Honnêtement, l’encadrement était, et est toujours, de mauvaise qualité. Une junior en 2026 peut demander « pourquoi ce code fait X » à 2 heures du matin sans culpabiliser. Elle peut lire plus de codebases plus vite. Elle obtient un questionnement socratique d’un tuteur patient sur chaque concept. Formaliser l’apprentissage autour de l’apprentissage assisté par IA pourrait, en principe, produire des ingénieurs plus solides plus vite.
Mais lire des explications ne se substitue pas à l’expérience. Il y a une différence entre savoir que les retries sans clé d’idempotence sont dangereux et avoir fait l’erreur et vu ton entreprise rembourser 40 000 €. Les ingénieurs seniors en qui j’ai le plus confiance ne sont pas ceux qui ont le plus lu ; ce sont ceux qui ont livré, cassé et réparé dans une grande variété de situations, formant ainsi leur jugement. Le modèle accélère la lecture. Il ne peut pas accélérer l’acquisition de l’expérience.
L’apprentissage assisté par IA peut fonctionner, mais il faut garder à l’esprit que l’IA est un amplificateur. Si l’apprentissage des juniors était déjà mauvais dans une entreprise, ce sera pire avec l’IA. Pour que cela fonctionne, l’organisation doit structurer délibérément l’accompagnement. Actuellement, la situation par défaut dans la plupart des organisations est de laisser les juniors optimiser leur vitesse de livraison avec l’IA, sans mettre en place les boucles de feedback ni protéger l’acquisition d’expérience.
Parallèles historiques
J’ai trouvé plusieurs parallèles instructifs, bien que limités.
Les comptables n’ont pas disparu face aux tableurs ; ils sont passés à l’audit et au conseil, défendus par deux siècles d’infrastructure d’apprentissage : certifications, stages et échelles structurées. Les architectes n’ont pas disparu face à la CAO ; ils sont passés du dessin à la main à la conception par ordinateur, ont mis en place des examens d’agrément et des ateliers de maquettes physiques qui imposent l’apprentissage des bases avant d’autoriser l’abstraction.
Le parallèle le plus proche est celui de la radiologie. Geoffrey Hinton avait prédit en 2016 que les radiologues seraient obsolètes dans cinq ans ; l’emploi en radiologie a au contraire crû, et l’ACR évoque désormais la pénurie de radiologues comme l’une des pressions définissant la profession. Sur la question du remplacement, le score est identique aux sept pierres tombales du logiciel.
Derrière le nombre de praticiens, le parcours de formation raconte une autre histoire. La profession utilise largement des systèmes IA qui fournissent un premier diagnostic avant toute analyse humaine. Les internes ne sont donc plus exposés à l’analyse complète des résultats à la recherche de signaux pour poser leur propre diagnostic. Le volume d’analyses augmente, la formation de la compétence se dégrade. C’est un sujet de plus en plus discuté au sein de la profession, car c’est cette lente acquisition d’une intuition et d’un jugement éclairé, patient après patient, qui fait d’un interne en radiologie un professionnel compétent. Il s’agit d’un problème de reproduction de la compétence, et non de remplacement par l’IA.
Pour y répondre, dans de nombreux pays, la radiologie dispose d’une infrastructure institutionnelle. Aux États-Unis, l’American Board of Radiology contrôle la certification, l’ACGME accrédite les résidences, l’American College of Radiology édicte les règles de la pratique. Quand la profession a remarqué la dérive de la formation, elle a pu y répondre en redessinant les cursus pour inclure une pratique délibérée sur des cas que l’IA a déjà analysés, en imposant des plages de lecture sans assistance et en suivant la performance des internes à travers les cohortes. La réponse est imparfaite et contestée, mais elle existe, et elle est pilotée de manière centralisée. Le monde du développement logiciel n’a rien d’équivalent. Il n’y a pas de licence d’ingénierie dans la plupart des juridictions, pas de corps professionnel ayant autorité sur la formation. L’apprentissage se déroule principalement à l’intérieur d’entreprises individuelles, varie, et ne suit souvent qu’un standard dicté par des entreprises qui sont en fait des cas particuliers, les GAFAM.
Le marché des ingénieurs seniors de 2035 n’a pas besoin d’être vide pour que le problème soit critique ; il a juste besoin d’être concentré. Là où le pipeline de la radiologie s’est rétréci et où la profession a pu répondre en tant que telle, le pipeline du développement logiciel se rétrécit et la réponse se fera au niveau de l’entreprise, de manière inégale. Les entreprises qui traitent le développement des juniors comme un investissement en capital dès maintenant auront des seniors au milieu des années 2030. Celles qui ne le font pas devront les acheter, au prix que le marché imposera. Pour le CTO d’une entreprise de la seconde catégorie, cela deviendra un problème de budget de recrutement à partir de 2031, quand la rareté commencera à tirer les budgets de recrutement vers le haut. La question à poser à ses pairs est de savoir dans quelle catégorie se trouve votre organisation.
L’absence de mémoire institutionnelle a rendu le pipeline fragile bien avant qu’un seul LLM ne soit entraîné. L’apprentissage dans le développement logiciel était déjà sous pression du fait des coupes budgétaires, bien avant que l’IA ait un impact réel sur la productivité. Le « Year of Efficiency » de Meta, les licenciements tech de 2023–2024 qui ont touché de manière disproportionnée les recrutements récents et la politique discrète et répandue de ne pas remplacer les postes de juniors en sont des exemples.
Le pipeline était mince avant l’IA. L’IA le rend plus mince.
Si ce scénario se confirme, 2035 verra une cohorte de seniors qualifiés sur le départ, une couche de mid-level creuse, et une cohorte de juniors qui n’aura jamais fait le travail mécanique qui en aurait fait les prochains seniors. Ce n’est pas une crise de remplacement. C’est une crise de reproduction. Cela ne ressemble en rien au scénario d’Amodei, et ce sont les décisions organisationnelles actuelles qui soit l’aggraveront, soit l’atténueront.
Ce que résoudre cela exige réellement
Résoudre le problème de reproduction ne nécessite pas de croire quoi que ce soit de particulier sur les limites de l’IA. Cela demande quatre engagements, qui se complètent dans un ordre précis : chacun ne fonctionne que si le précédent est en place.
Le premier est financier. Les ingénieurs juniors doivent être traités comme un investissement, pas comme un centre de coût sur l’année en cours. Cela signifie embaucher des juniors à un rythme qui dépasse ce que justifie le travail actuel, et protéger leur exposition au travail mécanique même quand une IA pourrait le faire plus vite. Le coût est réel et apparaît dès ce trimestre ; le bénéfice s’accumule comme une optionnalité sur un marché du travail que la plupart des organisations n’ont pas encore intégré dans leurs budgets. Il ne s’agit pas d’opposer dépense de formation et livraison trimestrielle, mais de se prémunir d’un risque de direction connue et de magnitude inconnue. La direction est connue : les ingénieurs seniors qui débogent aujourd’hui les systèmes de production sans assistance partiront à la retraite, et la cohorte derrière eux aura eu une exposition sans assistance mesurablement moindre. La magnitude, elle, ne l’est pas, et c’est précisément pourquoi c’est une couverture plutôt qu’une prévision. Les CFO comprennent l’optionnalité. La version de cet argument qui perd, c’est celle qui essaie de spécifier le premium sur les rôles senior de 2032 à deux décimales près ; la version qui gagne, c’est celle qui désigne l’incertitude elle-même comme la raison d’investir maintenant.
Le deuxième est managérial. Le mentorat doit être structuré plutôt qu’accidentel. À l’ère pré-IA, les juniors absorbaient le jugement des seniors par proximité, en regardant comment ils déboguaient, leurs commentaires en revue de code, leur façon de mener les débats sur le produit. Avoir une IA toujours disponible change la dynamique. La junior dispose désormais d’un substitut plus simple et rapide à la boucle de feedback avec un senior humain. Et elle dérivera naturellement vers ce substitut, sauf si l’organisation se structure contre la dérive. Cela signifie la mise en place de sessions de pair debugging, envisager la revue de code comme une source d’enseignement, créer les occasions d’aborder des problèmes difficiles dans un cadre contrôlé où l’erreur est acceptée, et du temps protégé pour que les seniors expliquent leur raisonnement à voix haute. C’est du travail d’engineering manager, et la plupart des organisations ne le font pas correctement aujourd’hui.
Le troisième, qui ne fonctionne que si les deux premiers sont en place, c’est la structure pour une pratique délibérée. La radiologie est le modèle : cursus de formation interne, pratique structurée de revue d’incidents, exercices de type « lis ce système de production et explique-le », et, de manière controversée, des périodes pendant lesquelles les juniors n’utilisent délibérément pas l’IA pour certains types de tâches. La controverse est réelle. L’alternative est pire. Sans les deux premiers engagements, le troisième est juste cher et performatif. Avec les trois, on permet à un junior de devenir senior dans un monde où l’exposition organique à la difficulté a chuté.
Le quatrième est celui qu’une ingénieure junior individuelle doit prendre pour elle-même, et aucun des engagements organisationnels ci-dessus ne le produit à lui seul. L’IA est en même temps un multiplicateur de productivité et un risque pour l’apprentissage. Chaque heure économisée en générant du code qui marche est une heure non passée à développer l’intuition de pourquoi le code marche. Le multiplicateur est réel. Le coût d’opportunité sur la formation des compétences l’est aussi. Les juniors qui reconnaissent ce trade-off investiront dans la lecture du code des autres, dans l’écriture du leur en partant de zéro parfois. Ils choisiront la voie lente même quand la voie rapide est disponible, dès lors qu’une tâche mobilise des compétences dont ils auront besoin dans le futur. Ceux qui ne le font pas augmenteront leur vélocité jusqu’à un certain seuil, sans accroître leur compétence. La différence apparaîtra autour de la cinquième année et leur progression de carrière en pâtira.
Rien de tout cela n’est garanti. La plupart des organisations optimisent pour le trimestre et continueront de sous-investir dans leur pipeline. La plupart des juniors prendront des raccourcis sans réfléchir sérieusement au coût pour leur carrière à moyen et long termes. La plupart des engineering managers n’ont jamais eu à penser explicitement à l’apprentissage, parce que l’ancienne version était souvent presque gratuite et auto-organisée. La transition vers un monde où l’apprentissage doit être une fonction délibérée au sein de l’ingénierie est un véritable changement organisationnel, qui se déroulera de manière inégale, et essentiellement invisible.
J’aimerais avoir tort sur ce point. Plus la profession développera organiquement une infrastructure de formation similaire à celle de la radiologie (partagée, portable, non propriétaire à une entreprise), moins l’offre d’ingénieurs seniors de 2035 sera concentrée. Je ne vois pas actuellement de mouvement vers une version partagée. Je vois des entreprises individuelles décider discrètement de protéger leurs propres pipelines, et les autres continuer à faire comme si le problème n’existait pas, croyant qu’il suffit d’attendre pour que les progrès de l’IA les sauvent de cette erreur.
Pour ceux qui dirigent une organisation d’ingénierie, voici les questions qui valent la peine d’être posées à l’équipe de direction, dès maintenant :
-
Quel est notre ratio junior/senior, et est-il soutenable aux taux d’embauche actuels ?
-
Combien de temps protégé nos seniors ont-ils pour enseigner, par opposition à livrer ?
-
Quel travail mécanique précis attendons-nous encore de nos juniors, même si l’IA pourrait le faire plus vite ?
-
Comment mesurons-nous la croissance de leur jugement, et pas seulement de leur output ?
-
Qui dans l’organisation est responsable du pipeline, comme un livrable distinct de la vélocité trimestrielle ?
Aucune de ces questions ne te demande de savoir si la prochaine prédiction d’Amodei se réalisera. Toutes ont des conséquences qui s’aggravent dans le temps.
La pierre tombale de Bromberg est toujours au Computer History Museum. Le nom dessus continue de changer : COBOL, le programmeur, le programmeur américain, l’ingénieur logiciel, le mid-level… L’occupant continue de manquer à l’appel. Mais le pipeline qui produit cet occupant est un autre monument, et la version 2035 de celui-ci est déjà en train d’être gravée, par des décisions que la plupart des organisations prennent sans même le réaliser.
Sources
Données de main-d’œuvre et de population aux États-Unis
- Beckhusen, J. (2016). Occupations in Information Technology. American Community Survey Reports ACS-35, US Census Bureau.
- US Bureau of Labor Statistics. Occupational Employment and Wages - May 2024. bls.gov/news.release/ocwage.htm
- BLS OEWS 15-1252 Software Developers ; 15-1251 Computer Programmers.
- BLS Occupational Outlook Handbook 2025-26, Software Developers.
- BLS Employment Projections 2024–2034.
- 1970 Census Subject Reports PC(2)-7A ; 1980 Census Supplementary Report PC80-S1-15 (1984) ; 1990 Census EEO File CP-S-1-1.
Prédictions historiques (sources primaires)
- Martin, J. (1982). Application Development Without Programmers. Prentice-Hall.
- Yourdon, E. (1992). Decline and Fall of the American Programmer. Prentice-Hall.
- Yourdon, E. (1996). Rise and Resurrection of the American Programmer. Prentice-Hall.
- McCarthy, J. C. (11 novembre 2002). 3.3 Million U.S. Services Jobs To Go Offshore. Forrester Research.
- Gartner, By 2024, 80% of Technology Products and Services Will Be Built by Professionals Outside of IT (10 juin 2021).
- Huang, J. (12 février 2024). World Government Summit Dubai.
- Zuckerberg sur Joe Rogan Experience #2255 (10 janvier 2025).
- Amodei, D. (10 mars 2025). Council on Foreign Relations.
CASE, 4GL, VB
- Iivari, J. (1996). « Why are CASE tools not used? » CACM 39(10):94–103.
- Kemerer, C. F. (1992). « How the learning curve affects CASE tool adoption. » IEEE Software 9(3):23–28.
- Retool, Something Pretty Right: A History of Visual Basic.
Déclarations et rétractations sur la vague IA actuelle
- Nadella, S. (29 avril 2025) à Meta LlamaCon.
- Conférence sur les résultats d’Alphabet Q3 2024 (29 octobre 2024).
- Rétractation IA de Klarna (mai 2025).
- Jassy, A. (17 juin 2025). Mémo aux employés d’Amazon.
Études empiriques sur la productivité et la qualité avec l’IA
- Becker, J., Rush, N., Barnes, E., & Rein, D. (10 juillet 2025). « Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. » METR. arXiv:2507.09089.
- Étude de suivi METR (24 février 2026).
- Rapport DORA 2024 ; rapport DORA 2025.
- GitClear (janvier 2024). Coding on Copilot. GitClear (février 2025). AI Copilot Code Quality: 2025 Data.
- Stack Overflow Developer Survey 2024 ; 2025.
- Faros AI, AI Productivity Paradox Report 2025 ; AI Engineering Report 2026.
Études d’exposition du marché du travail à l’IA
- Eloundou, T., Manning, S., Mishkin, P., & Rock, D. (2024). « GPTs are GPTs: Labor Market Impact Potential of Large Language Models. » Science. arXiv:2303.10130.
- Goldman Sachs (Briggs & Kodnani, mars 2023). The Potentially Large Effects of AI on Economic Growth.
- McKinsey Global Institute (juillet 2023). Generative AI and the Future of Work in America.
- World Economic Forum (janvier 2025). Future of Jobs Report 2025.
- Yale Budget Lab (janvier 2026). Labor Market AI Exposure: What Do We Know?
Économie du travail et analyse de classe du travail logiciel
- Ensmenger, N. (2010). The Computer Boys Take Over. MIT Press.
- Braverman, H. (1974). Labor and Monopoly Capital. Monthly Review Press.
- Benanav, A. (2020). Automation and the Future of Work. Verso.
- Pasquinelli, M. (2023). The Eye of the Master. Verso.
Contre-tradition — l’angoisse de l’automatisation comme mauvaise prévision
- Autor, D. (2015). « Why Are There Still So Many Jobs? » Journal of Economic Perspectives 29(3).
- Bessen, J. (2019). « Automation and Jobs: When Technology Boosts Employment. » Economic Policy.
- Mokyr, J., Vickers, C., & Ziebarth, N. L. (2015). « The History of Technological Anxiety and the Future of Economic Growth. » Journal of Economic Perspectives 29(3).
Explications structurelles de la focalisation sur le code dans l’IA
- Classement SWE-Bench Verified, Princeton NLP / OpenAI.
- Annonce de financement d’Anthropic (2025).
- Statistiques d’abonnés à GitHub Copilot 2026.
- Parts de marché des assistants de code IA 2026.
Autres
- Croissance de l’emploi des radiologues depuis la prédiction de Hinton en 2016 — couverture dans The New Republic et CNN (2026).
- Bromberg, H., Hopper, G. M., Jones, J. L., & Nelson, D. The Story of the COBOL Tombstone. Transcription de la célébration du 25e anniversaire de COBOL au Computer Museum, 16 mai 1985. Computer History Museum.
- Drezner, D. W. (mai/juin 2004). « The Outsourcing Bogeyman. » Foreign Affairs.